Introduction
Obtaining soil parameters for SWAT+ model can be difficult. Therefore package has functions with allows automatic preparation of soil parameters. Important theoretical documentation for the equations is presented in the section 3.4 of SWAT+ modelling protocol.
For populating SWAT+ usersoil parameter table SOL_Z (depth of layer), CLAY (percentage of clay defined as particles <2 ), SAND (percentage of sand - 50–2000 ), SILT (percentage of silt - 2–50 ) and OC (same as SOL_CBN, soil organic carbon content in %) parameters should be collected per each separate soil type profile’s layer. Other parameters will be filled by get_usersoil_table. For assigning Hydrologic Soil Groups tile drainage, water level and impervious layer depth data are needed.
The preparation of soil data and parameters could be done using following workflow. However, depending on available types of data, different steps might needed. This is an example of Polish case study of Upper Zglowiaczka in OPTAIN project.
Loading libraries and paths to data
Workflow presented here needs 6 R packages. However, only
SWATprepR and euptf2 libraries are required
for the population of soil parameter’s table with get_usersoil_table
presented in Adding soil parameters to user
table step. Input for this step could be prepared in various ways.
Here is presented just one of the way to understand better all work
process to develop soil parameters table.
##Required
library(SWATprepR)
library(euptf2)
##Optional
library(sf)
library(readxl)
library(tidyverse)
library(stars)
##Required
##Path to soil distribution shape file
soil_path <- system.file("extdata", "GIS/soils.shp", package = "SWATprepR")
##Path to soil lookup initial parameters with SOL_Z, CLAY, SILT, OC parameters filled.
lookup_path <- system.file("extdata", "soil_lookup.xlsx", package = "SWATprepR")
##Path to tile drainage shape file
drainage_path <- system.file("extdata", "GIS/drained.shp", package = "SWATprepR")
##Optional
##Path to water level depth shape file
water_l_path <- system.file("extdata", "GIS/water_level.shp", package = "SWATprepR")
##Path to DEM raster file
DEM_path <- system.file("extdata", "GIS/DEM.tif", package = "SWATprepR")
##Path to catchment boundary shape file (which in this case used as impervious layer data)
basin_path <- system.file("extdata", "GIS/basin.shp", package = "SWATprepR")
##Path to soil hydro groups (if available)
hsg_path <- system.file("extdata", "GIS/hydgrp.shp", package = "SWATprepR")Preparing input data
Lookup table contains two sheets. One about granulometry (SAND, SILT, CLAY content) of each soil texture class. Second about humus content in different humus class soils (distributed through layers), which could be easily recalculated to organic carbon content (with division by 1.72 coefficient).
##Reading granulometry lookup information for soil types into dataframe
gran <- read_excel(lookup_path, sheet = "SandSiltClay")
##Print example of gran table
print(head(gran, 3))## # A tibble: 3 × 4
## `Texture EN` SAND SILT CLAY
## <chr> <dbl> <dbl> <dbl>
## 1 CL 32.0 42.9 25.1
## 2 L 52.3 29.4 18.2
## 3 LS1 87.2 10.3 2.46
##Reading humus lookup information in to dataframe and converting it into organic carbon %.
humus <- read_excel(lookup_path, sheet = "Humus") %>%
mutate(OC1 = `Humus 1st layer [%]`/1.72,
OC2 = `Humus 2nd layer [%]`/1.72,
OC3 = `Humus 3rd layer [%]`/1.72) %>%
select(Humus, starts_with("OC"))
##Print example of humus table
print(head(humus, 3))## # A tibble: 3 × 4
## Humus OC1 OC2 OC3
## <dbl> <dbl> <dbl> <dbl>
## 1 1 1.88 0.942 0.174
## 2 2 1.63 0.814 0.151
## 3 3 1.26 0.628 0.116
##Reading GIS layers for basin boundary, water level, drainage status, soils (with "Code" column here representing soil types) and soil hydrological groups.
##All data should be in one coordinate system.
##Impervious layer is prepared from basin layer as it is below 1 m whole catchment falls into one category.
impervious<- st_read(basin_path, quiet = TRUE) %>%
mutate(Impervious = ">100cm") %>%
st_transform(3035)
water_level <- st_read(water_l_path, quiet = TRUE) %>%
st_transform(3035)
drainage <- st_read(drainage_path, quiet = TRUE) %>%
st_transform(3035)
soils <- st_read(soil_path, quiet = TRUE) %>%
st_transform(3035)
hsg <- st_read(hsg_path, quiet = TRUE) %>%
st_transform(3035)All required GIS input data are presented in the maps below. Polygons in the impervious layer should have one of three possible categories: “<50cm”, “50-100cm” and “>100cm”. If no information is available impervious layer depth could be assumed to be the depth of last soil layer and then reclassified into one of the three categories. Water level depth also should have only three categories: “<60cm”, “60-100cm” and “>100cm”. If information is not available soil types and land use could serve as a good proxy for this information. For instance wet areas as wetlands could probably be assigned with “<60cm” class, areas with dominant organic soils with “60-100cm”, etc. Drainage status should be divided into two: “Y” for drained areas, “N” for areas without working tile drains. If no database available, information about existence of drains might be available in drainage installation plans.
##Preparing maps for each GIS data
p1 <- ggplot(impervious) +
geom_sf(mapping = aes(fill = Impervious)) +
theme_void()
p2 <- ggplot(water_level) +
geom_sf(mapping = aes(fill = Depth)) +
theme_void()
p3 <- ggplot(drainage) +
geom_sf(mapping = aes(fill = Drained)) +
theme_void()
p4 <- ggplot(soils) +
geom_sf(mapping = aes(fill = Code), show.legend = F) +
theme_void()
##Combining into one
cowplot::plot_grid(p1, p2, p3, p4, ncol = 2,
labels = c('Impervious depth', 'Water level', 'Drainage status', 'Soil types'),
label_x = 0, label_y = 0, hjust = -0.1, vjust = -0.5, label_size = 10)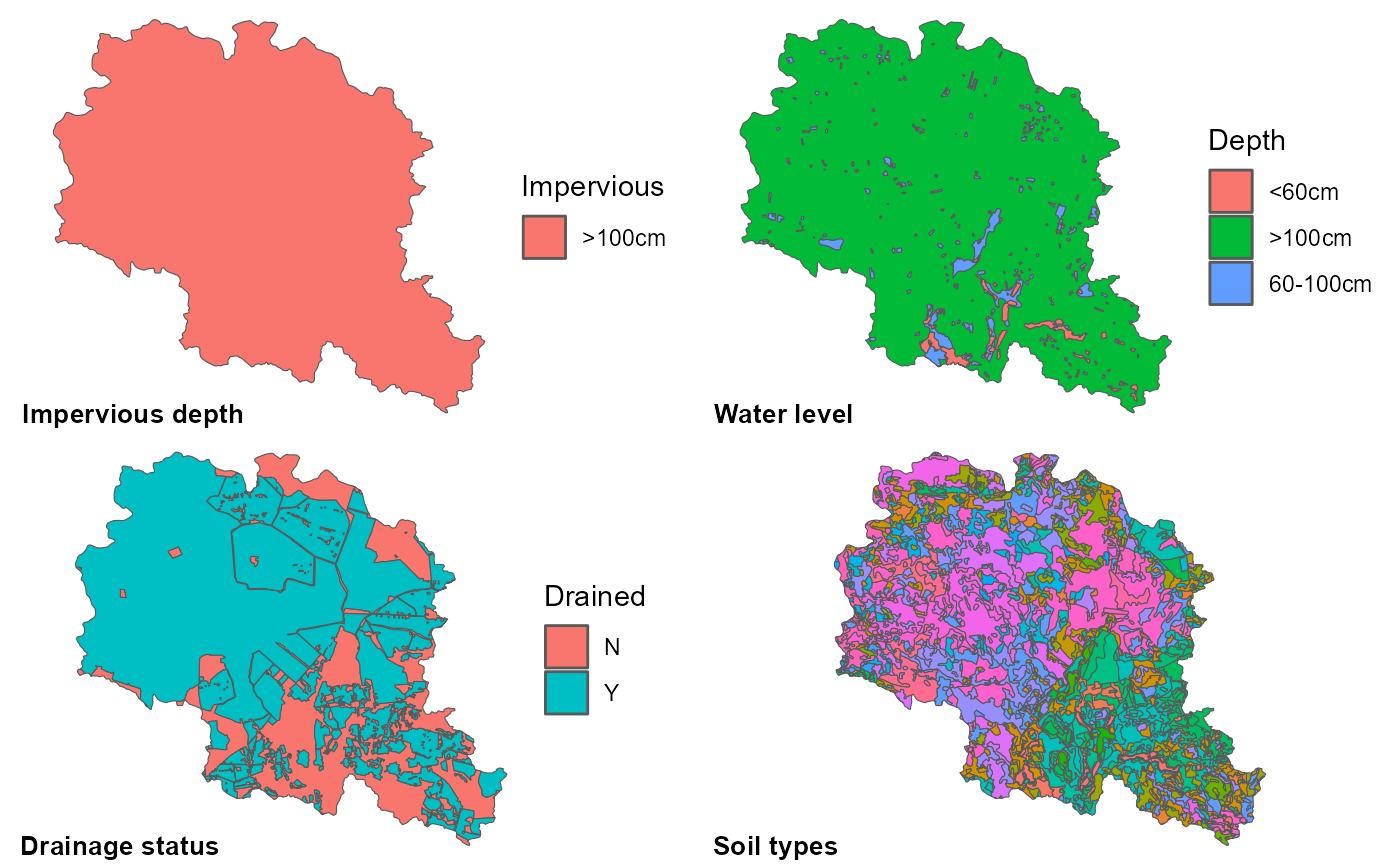
Preparing final soil layer
The final soil layer should have information added from GIS layers to soil types. For instance in our example initial soil type code has 4 elements separated by “_“. So it looks as S3_S3_SL3_3. First three shows texture class of soil granulometry three layers and the last number humus class.
##Printing example of soil codes before intersection
print(head(soils %>% st_drop_geometry(), 3))## OBJECTID Code Shape_Leng Shape_Area
## 1 1 S3_S3_SL3_3 546.3484 11186.102
## 2 2 SL2_S3_SL3_3 356.2983 4183.884
## 3 3 SL3_SL3_SL3_1 2152.1265 99806.207
##Counting number of unique soil types in input soil data
soils_n1 <- dim(soils %>% st_drop_geometry() %>% select(Code) %>% unique)[1]
##Intersecting soil types with other layers
soils <- soils %>%
st_intersection(impervious) %>%
st_intersection(water_level) %>%
st_intersection(drainage) %>%
mutate(SNAM = paste0(Code, "_", Impervious, "_", Depth, "_", Drained)) %>%
select(SNAM)
##Dealing with different possible geometries to clean up the layer produced by
##intersection. Following lines is needed to extract nested geometries and
##convert them into multipolygons.
soils_g1 <- soils %>%
filter(grepl("GEOMETRYCOLLECTION", st_geometry_type(geometry))) %>%
st_collection_extract(., "POLYGON") %>%
st_cast("MULTIPOLYGON")
##Selecting only polygons geometry types and converting them into multipolygons.
soils_g2 <- soils %>%
filter(!grepl("POINT|LINESTRING|GEOMETRYCOLLECTION", st_geometry_type(geometry))) %>%
st_cast("MULTIPOLYGON")
##Binding all geometries together
soils <- bind_rows(soils_g1, soils_g2)
row.names(soils) <- NULL
##Counting number of unique soil types in generated soil data
soils_n2 <- dim(soils %>% st_drop_geometry() %>% select(SNAM) %>% unique)[1]After intersection with other GIS layers information for them is added to the soil code. Thus generating new soil type, which have information about water, impervious layer depth, drainage status as well. For instance a new code is S3_S3_SL3_3_>100cm_60-100cm_Y. So the first four elements stay the same and the last three added should be depth to impervious layers, depth to water level and drainage status classes. It is important to point out that intersection with GIS layers in this example increased number of unique soil types from 171 to 543 and a new soil type distribution GIS data have been created.
##Example of new soil codes
print(head(soils %>% st_drop_geometry(), 3))## SNAM
## 1 S1_S1_S1_5_>100cm_>100cm_N
## 2 S1_S1_S1_5_>100cm_>100cm_N
## 3 S1_S1_S1_5_>100cm_>100cm_N
##Preparing figure of new soil data
p5 <- ggplot(soils) +
geom_sf(mapping = aes(fill = SNAM), show.legend = F) +
theme_void()
cowplot::plot_grid(p4, p5, ncol = 2,
labels = c('Original soil map', 'New soil map'),
label_x = 0, label_y = 0, hjust = -0.1, vjust = -0.5, label_size = 10)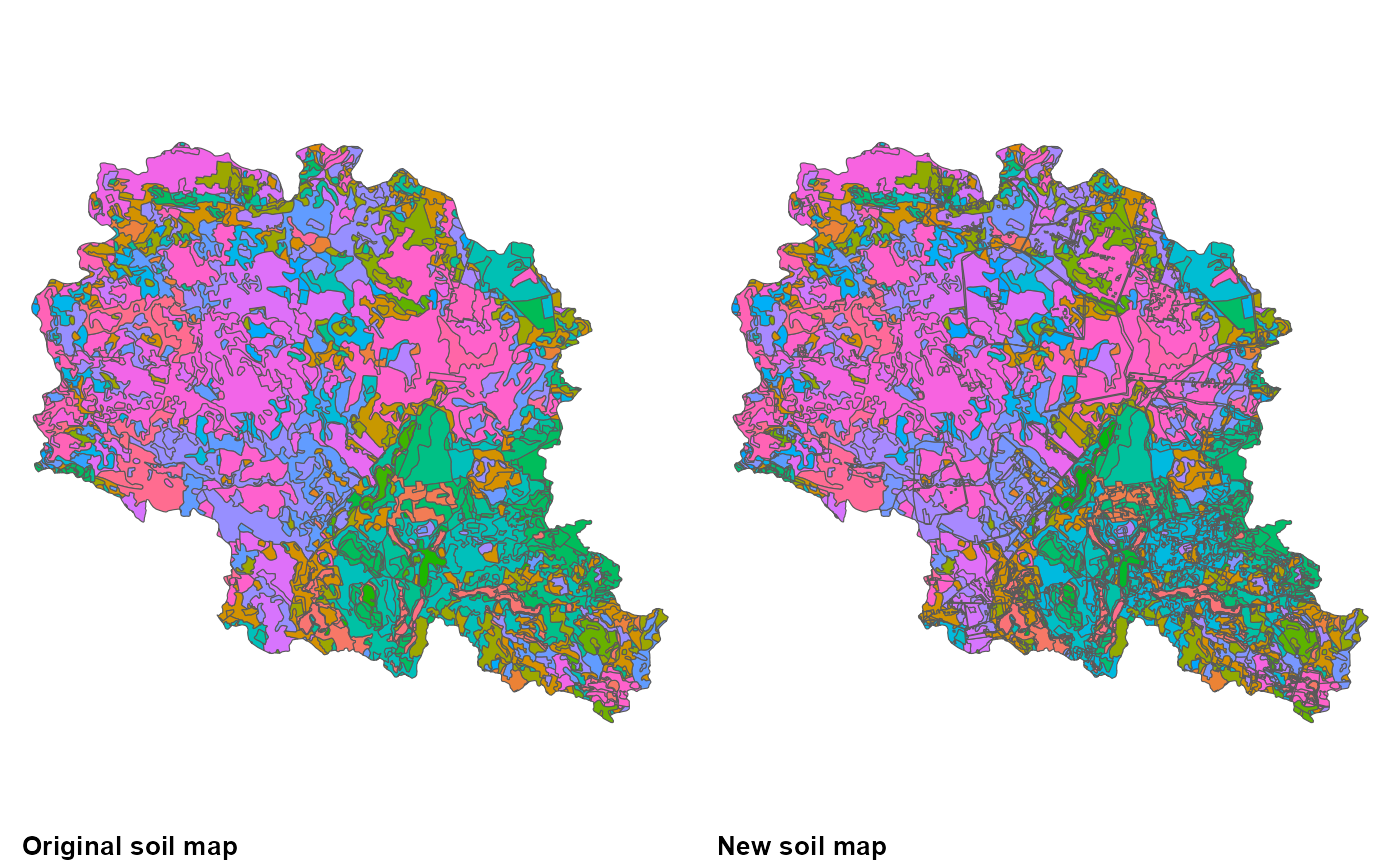
Preparing initial user soil table
This part prepares input for the following parameter generation part, which actually uses
SWATprepR package functions to populate usersoil table.
Workflow provided up to here was done to form input to
usertable, which could be used with get_usersoil_table
function. However, such this information could be prepared with other
means than R, which might be more convenient to user and then loaded
into R environment. The only requirements for table to have these
parameters filled:
- SNAM soil type text with last three parts separated by **_** representing impervious layer, water level and drainage classes;
- NLAYERS numeric value for soil type representing number of soil layers;
- For each layer in soil type profile:
- SOL_Z numeric value for soil layer to represent max depth of soil layer;
- SAND numeric sand content in %;
- SILT numeric silt content in %;
- CLAY numeric clay content in %;
- SOL_CBN numeric organic carbon content in %.
The example below demonstrates how data from lookup tables could be
used to populate initial usertable and how it should look
before generating other parameters. In our case all soil types had three
layers with same depth. So this information added with
mutate function. Then according textural classes lookup
information was added to table with left_join
functions.
usertable <- soils %>%
st_drop_geometry() %>%
distinct() %>%
separate(SNAM, c("Lyr1", "Lyr2", "Lyr3", "Humus", "Impervious", "Depth", "Drained"), "_", remove = FALSE) %>%
mutate(NLAYERS = 3,
SOL_Z1 = 250,
SOL_Z2 = 750,
SOL_Z3 = 1500,
Humus = as.numeric(Humus)) %>%
left_join(gran %>% rename_with( ~ paste0(.x, "1")), by = c("Lyr1" = "Texture EN1")) %>%
left_join(gran %>% rename_with( ~ paste0(.x, "2")), by = c("Lyr2" = "Texture EN2")) %>%
left_join(gran %>% rename_with( ~ paste0(.x, "3")), by = c("Lyr3" = "Texture EN3")) %>%
left_join(humus, by = c("Humus")) %>%
mutate(Impervious = str_split(SNAM, "_")[[1]][5],
Depth = str_split(SNAM, "_")[[1]][6],
Drained = str_split(SNAM, "_")[[1]][7]) %>%
select(SNAM, NLAYERS, Impervious, Depth, Drained, ends_with("1"), ends_with("2"), ends_with("3"), -starts_with("Lyr"))
##Renaming OC column to SOL_CBN
sol_oc <- names(usertable)[grep("OC>*", names(usertable))]
usertable <- rename_at(usertable, vars(all_of(sol_oc)), ~sub("OC", "SOL_CBN", sol_oc))
##Saving and printing structure example of the required table
write.csv(usertable, "../output/usersoils.csv", row.names=FALSE, quote=FALSE)
str(usertable)## 'data.frame': 543 obs. of 20 variables:
## $ SNAM : chr "S1_S1_S1_5_>100cm_>100cm_N" "LS2_S3_SL3_3_>100cm_>100cm_N" "Emt_Emt_Emt_7_>100cm_>100cm_N" "Mpl_S1_S1_8_>100cm_>100cm_N" ...
## $ NLAYERS : num 3 3 3 3 3 3 3 3 3 3 ...
## $ Impervious: chr ">100cm" ">100cm" ">100cm" ">100cm" ...
## $ Depth : chr ">100cm" ">100cm" ">100cm" ">100cm" ...
## $ Drained : chr "N" "N" "N" "N" ...
## $ SOL_Z1 : num 250 250 250 250 250 250 250 250 250 250 ...
## $ SAND1 : num 95.4 80.7 0 89 74.5 ...
## $ SILT1 : num 3.46 14.84 0 6 19.61 ...
## $ CLAY1 : num 1.15 4.45 50 5 5.86 ...
## $ SOL_CBN1 : num 0.628 1.256 8.721 5.814 1.256 ...
## $ SOL_Z2 : num 750 750 750 750 750 750 750 750 750 750 ...
## $ SAND2 : num 95.4 87.3 0 95.4 62.5 ...
## $ SILT2 : num 3.46 10.04 0 3.46 25.39 ...
## $ CLAY2 : num 1.15 2.65 50 1.15 12.07 ...
## $ SOL_CBN2 : num 0.314 0.628 4.36 2.907 0.628 ...
## $ SOL_Z3 : num 1500 1500 1500 1500 1500 1500 1500 1500 1500 1500 ...
## $ SAND3 : num 95.4 62.5 0 95.4 62.5 ...
## $ SILT3 : num 3.46 25.39 0 3.46 25.39 ...
## $ CLAY3 : num 1.15 12.07 50 1.15 12.07 ...
## $ SOL_CBN3 : num 0.0581 0.1163 0.8721 0.5814 0.1163 ...Adding soil parameters to user table
This section is the only required part and is the essence of the workflow. In it get_usersoil_table function is filling all required SWAT+ parameters. If input data is formatted correctly, function is very straightforward. It requires only prepared csv file.
usertable <- get_usersoil_table("../output/usersoils.csv", hsg = TRUE, keep_values = FALSE, nb_lyr = 10)## [1] "Soil hydrological groups were calculated."
## [1] "Adding additional 7 layer(s) added."Overwritting with measured parameters
In case some soil types do have have required soil parameters get_usersoil_table
function results can be overwritten. Example below provides example data
and code to be used for replacing parameters in the generated user
table. However, the same could be achieved with
keep_values = TRUE in get_usersoil_table
function, if data were provided in ‘usersoils.csv’ file used as
input for the function.
##Example data loaded to be used for overwriting parameters in the user table
rep_pars_path <- system.file("extdata", "soil_parameters.xlsx", package = "SWATprepR")
replace_pars <- read_excel(rep_pars_path)
##Extracting soil type codes for each soil layer
usertable <- separate(usertable, SNAM, c("Lyr1", "Lyr2", "Lyr3", "LyrX"), "_", extra = "merge", remove = FALSE)
##Replacing values for selected soil types
for(p in c("Emt", "Mpl", "Tn")){
##Selected soil layers
for (l in seq(1, 3)){
##Selected parameters
mp <- paste0(c("SOL_Z", "SOL_BD", "SOL_AWC", "SOL_K", "SOL_CBN", "CLAY",
"SILT", "SAND", "ROCK", "SOL_ALB", "USLE_K", "SOL_EC"),l)
usertable[usertable[paste0("Lyr",l)] == p, mp] <- replace_pars[replace_pars["SNAM"] == p, mp]
}
}
##Removing columns with soil types for each layer
usertable <- select(usertable, -starts_with("Lyr"))If case of some parameters are available from GIS data (i.e. from field measurements or local databases), they can be used by overwriting generated parameters in the usertable. In our example we had map of soil hydrological groups. It was used to overwrite results from get_soil_parameters function.
##Joining GIS data to generated usertable
soilp <- soils %>% left_join(usertable, by = "SNAM")
##Plotting soil hydrologic groups obtained from get_usersoil_table function
plot(soilp["HYDGRP"], main="HYDGRP obtained with get_usersoil_table function")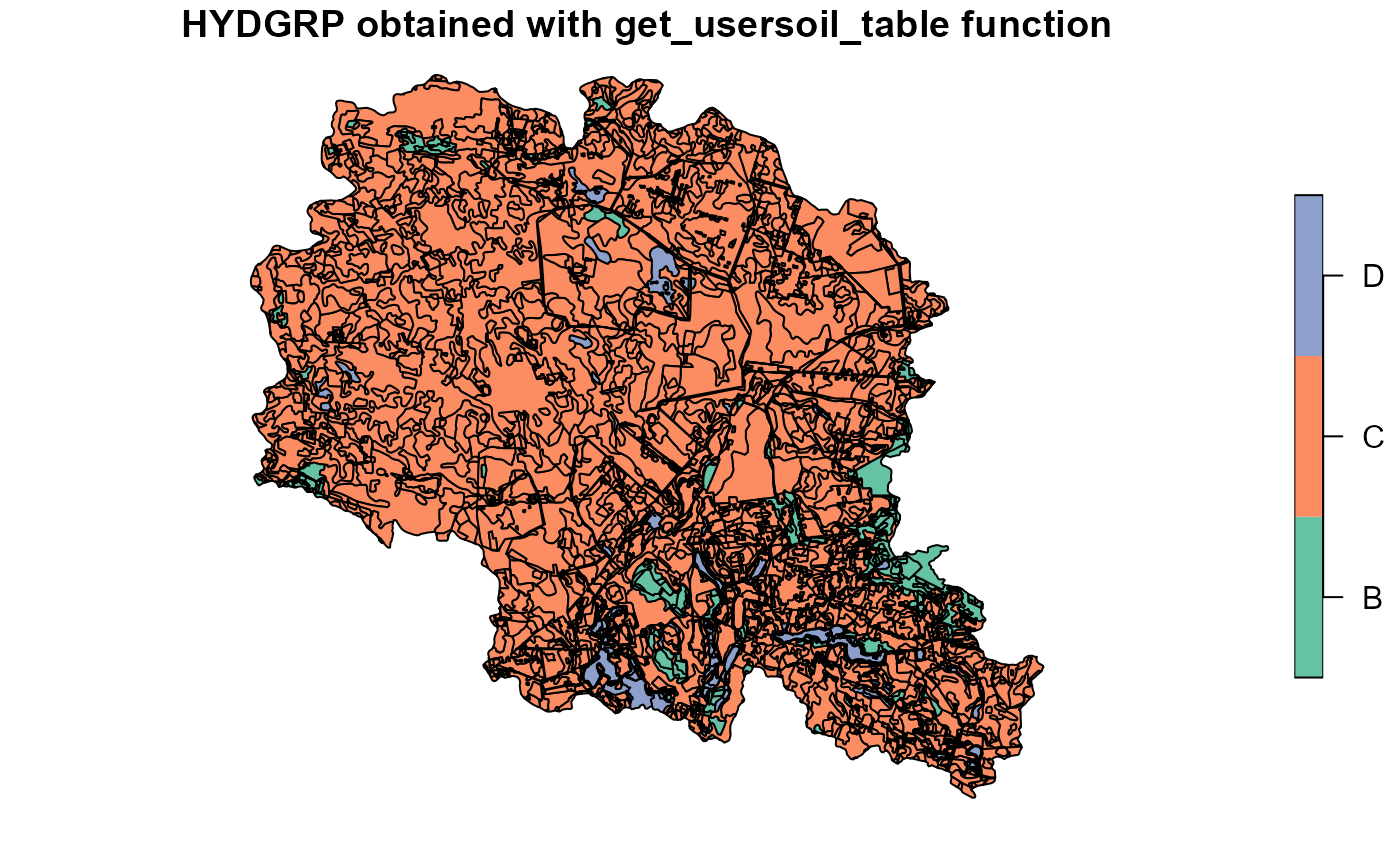
##Plotting soil hydrologic groups obtained local hydgrp map
plot(hsg["hsg"], main="HYDGRP from field data")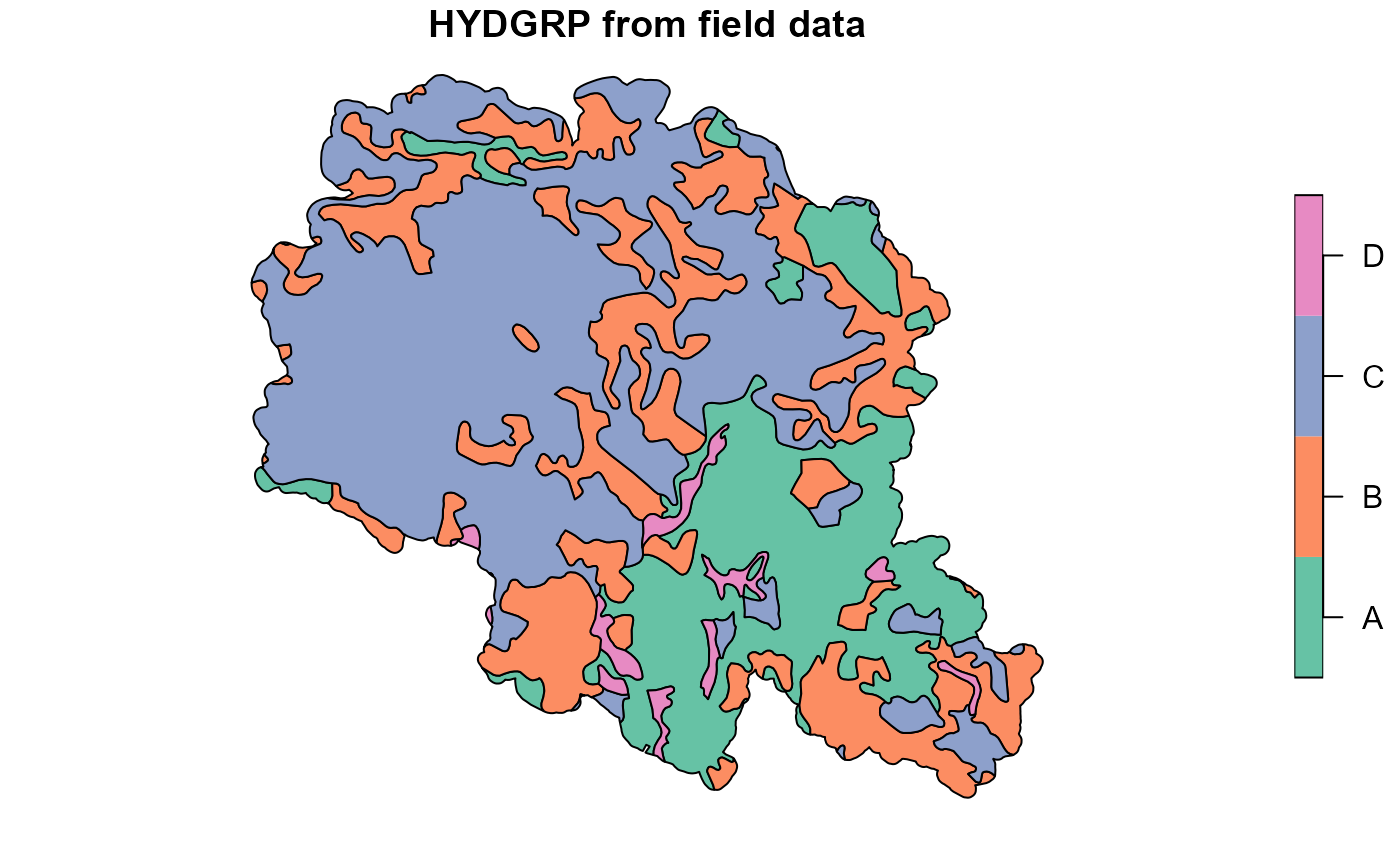
##Overwriting generated data with values from field data source
soilp <- st_join(soilp, hsg, join = st_overlaps, left = TRUE, largest = TRUE) %>%
mutate(HYDGRP = hsg) %>%
select(-hsg)
##Updating soil type names with hydrologic groups as to save this information,
##in following steps.
soilp$SNAM <- paste0(soilp$SNAM, "_", soilp$HYDGRP)
##Plotting updated data result
plot(soilp["HYDGRP"])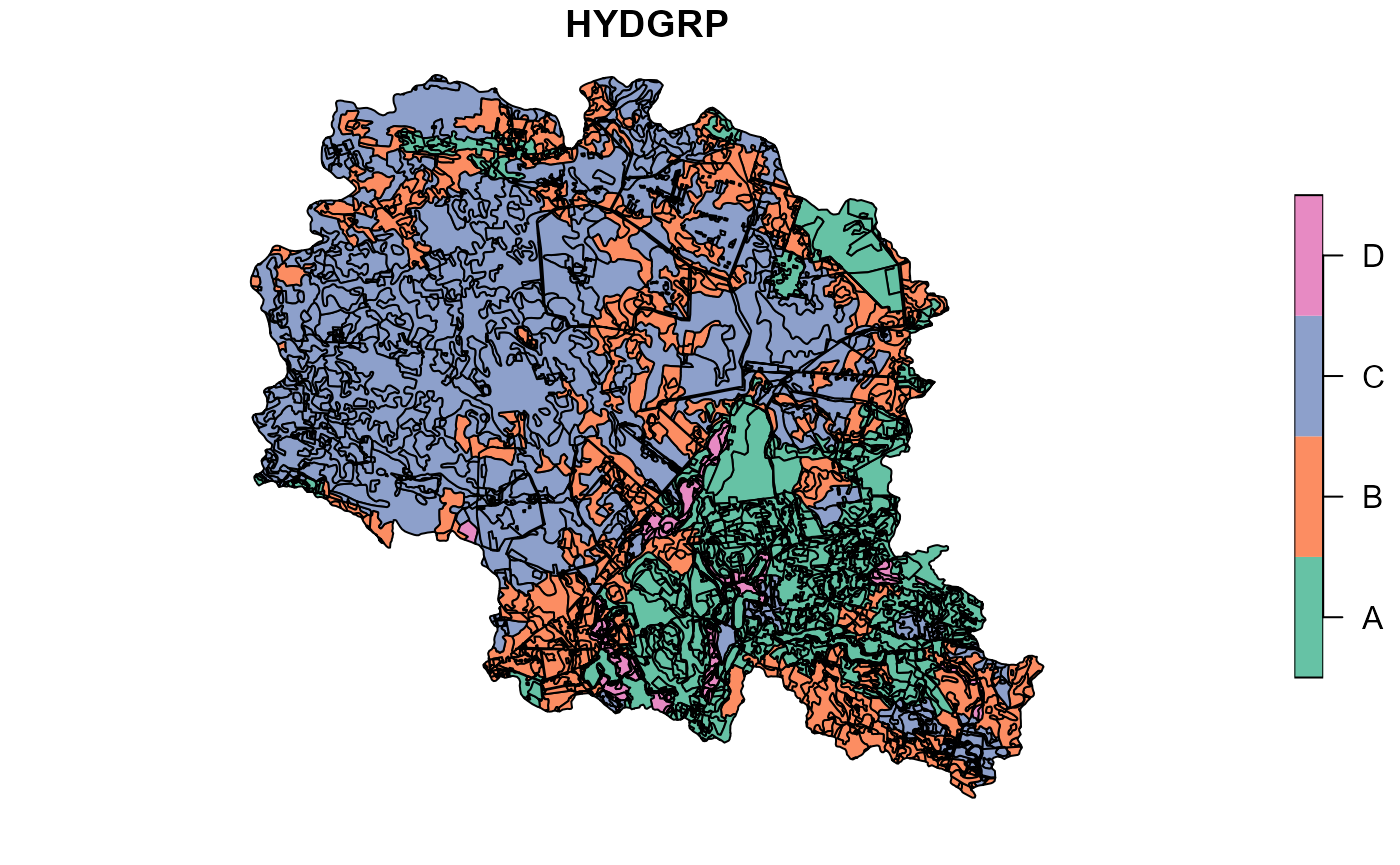
Checking results on a map
After generation of all required soil parameters checking of results on a map is a good practice, which could help to spot various issues and validate results. Below are just few examples.
##Plot soil sol_k for the top layer
plot(soilp["SOL_K1"])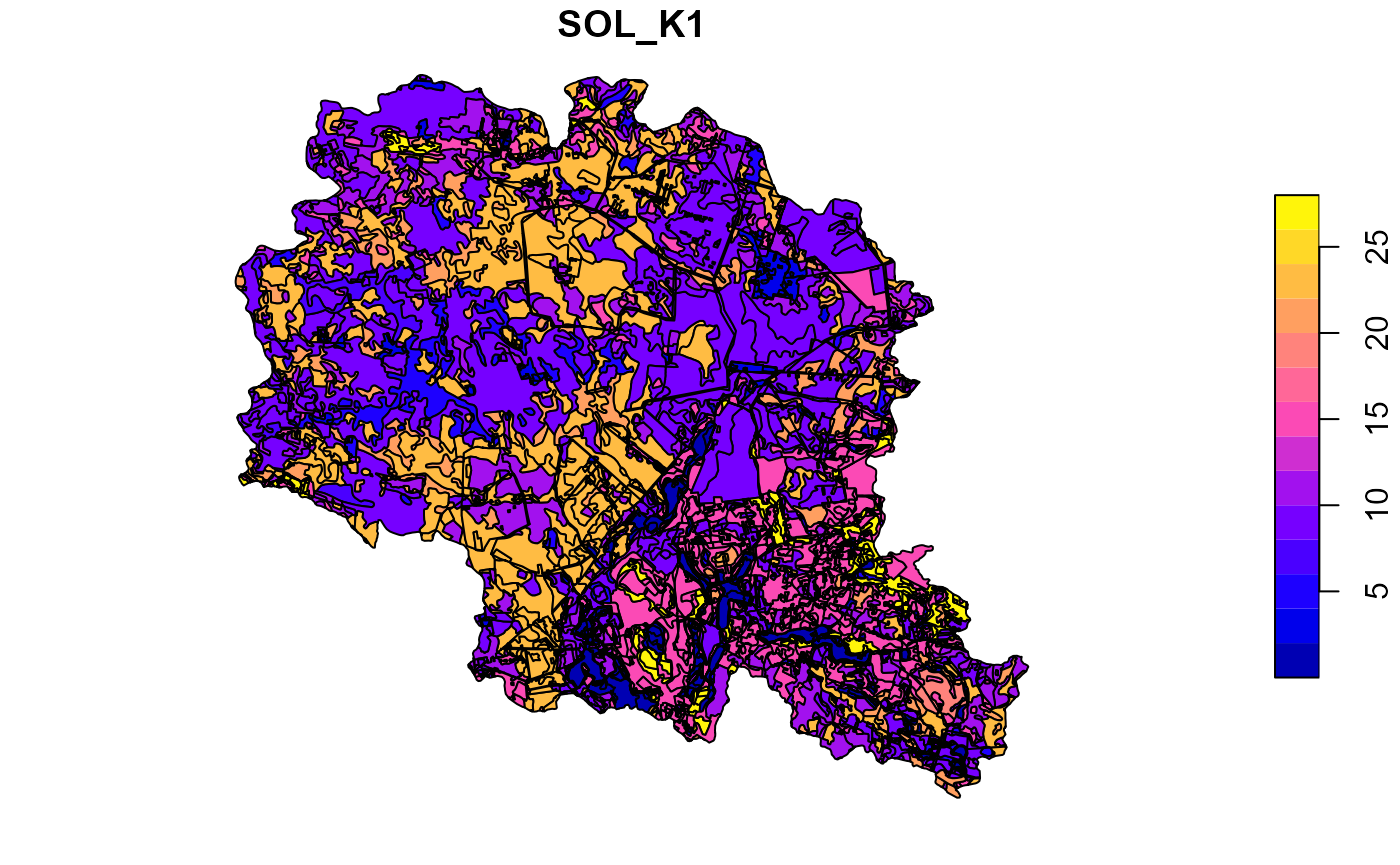
##Plot soil sol_k for the top layer
plot(soilp["USLE_K1"])
##Plot soil sol_awc for the top layer
plot(soilp["SOL_AWC1"])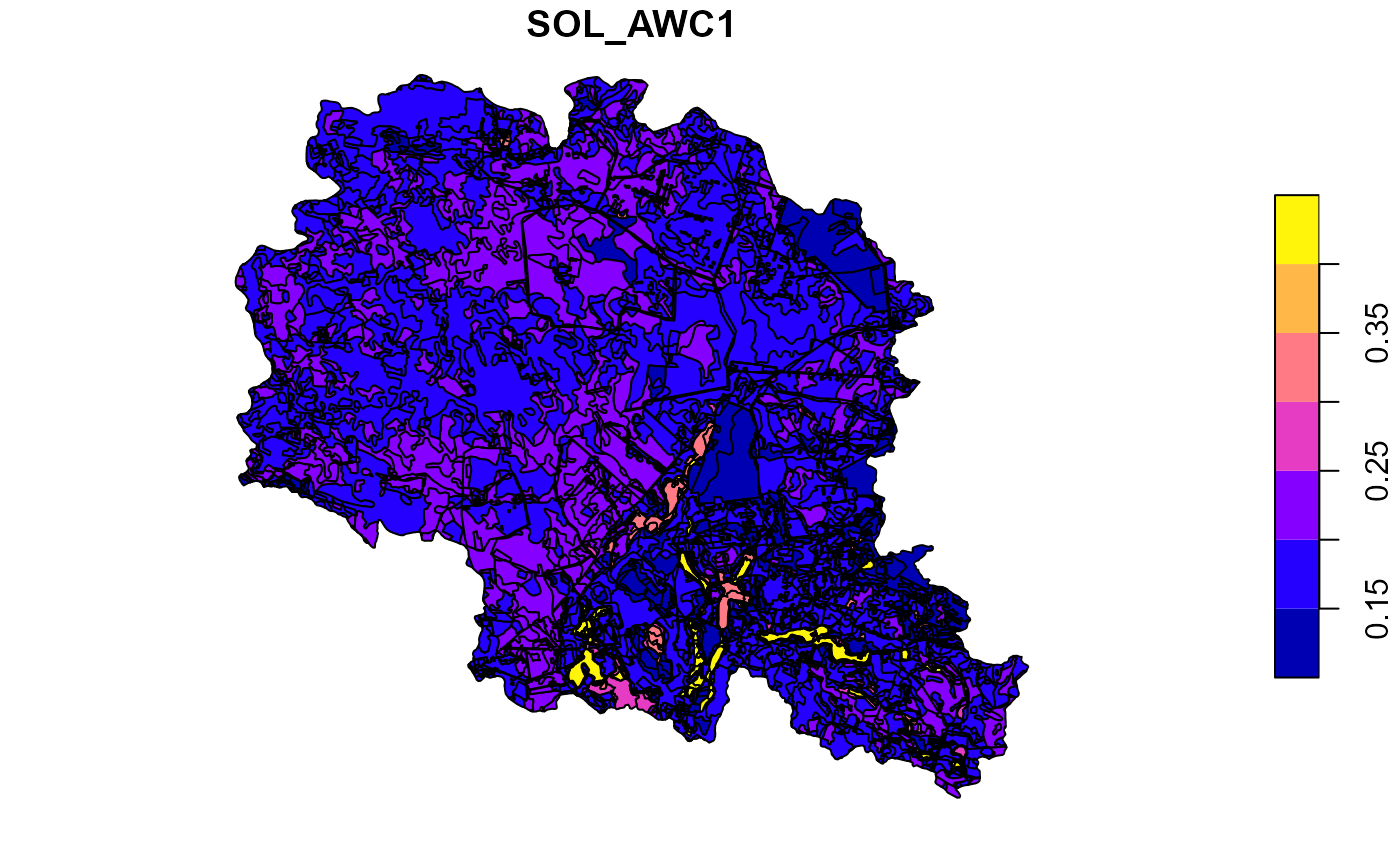
Write inputs for SWAT+
The very last step is to write SWAT+ input data: raster layer (in our case named as ‘SoilmapSWAT.tif’), linkage table between raster codes and soil type codes (‘Soil_SWAT_cod.csv’) and usersoil table (‘usersoil_lrew.csv’). DEM data in this step is used to help rastarize soil types distribution to grid, which will be used by setup preparation algorithms.
##Reading catchment DEM raster data
dem <- read_stars(DEM_path)
plot(dem)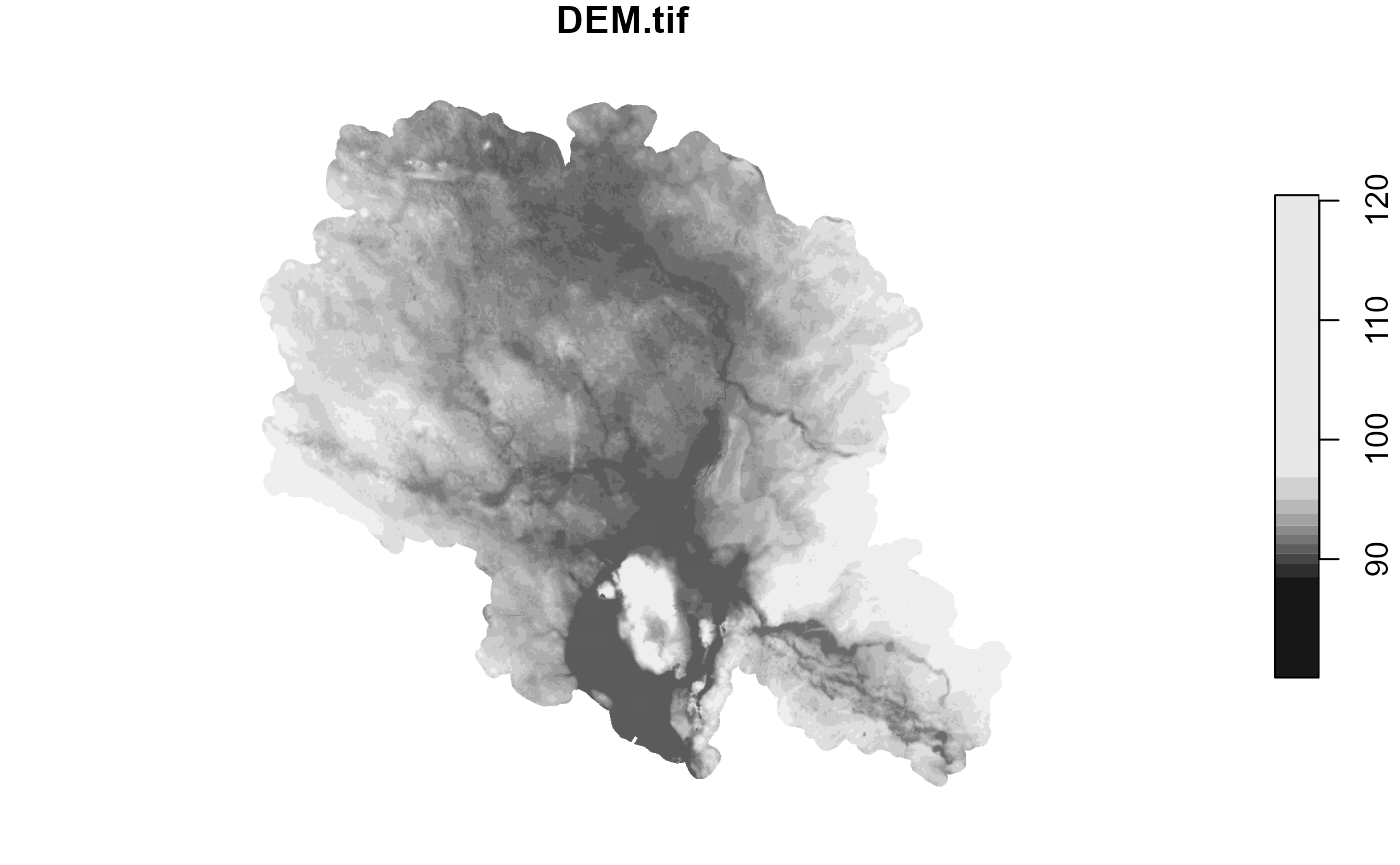
##Merging unique soil types into one row and multipolygon
soils_dis <- soilp %>%
group_by(SNAM) %>%
dplyr::summarise() %>%
mutate(SOIL_ID = rownames(.),
SNAME = SNAM)
##Rasterizing soil type data
soils_raster <- soils_dis %>%
st_rasterize(dem)
plot(soils_raster)
##Preparing linkage table
soil_link_table <- soils_dis %>%
st_drop_geometry() %>%
rename(`Soil full name` = SNAM) %>%
mutate(SNAM = paste0("s",SOIL_ID)) %>% ## rename soil codes as SWAT+ takes max 20 chr.
select(SOIL_ID, SNAM, `Soil full name`)
print(head(soil_link_table, 3))## # A tibble: 3 × 3
## SOIL_ID SNAM `Soil full name`
## <chr> <chr> <chr>
## 1 1 s1 Emt_Emt_Emt_1_>100cm_<60cm_N_A
## 2 2 s2 Emt_Emt_Emt_1_>100cm_<60cm_N_B
## 3 3 s3 Emt_Emt_Emt_1_>100cm_<60cm_Y_B
##Preparing updated user soil table
usertable_to_save <- soil_link_table %>%
left_join(soilp %>% st_drop_geometry(), by = c("Soil full name" = "SNAM")) %>%
distinct(SNAM, .keep_all = TRUE) %>%
mutate(OBJECTID = as.numeric(SOIL_ID)) %>%
arrange(OBJECTID) %>%
select(OBJECTID, MUID,SEQN,everything(), -c("SOIL_ID", "Soil full name"))write_stars function from stars package
could be used to write raster file and write.csv R base
function to write .csv files.
##Writing files
write_stars(soils_raster , "../output/SoilmapSWAT.tif")
write.csv(soil_link_table[c(1:2)], "../output/Soil_SWAT_cod.csv", row.names=FALSE, quote=FALSE)
write.csv(usertable_to_save, "../output/usersoil_lrew.csv", row.names=FALSE, quote=FALSE)
##Saving short soil names link to full names
write.csv(soil_link_table[c(2:3)], "../output/Soil_short_to_full.csv", row.names=FALSE, quote=FALSE)